메모리 구조
물리적 메모리
하드 디스크 : 디스크 저장 장치. 메인 메모리인 RAM에 적재되는 데이터를 저장. (SSD, HDD)
RAM : 메인 메모리. RAM에 적재된 데이터는 CPU 칩에 젖아된 캐시(cache)라는 메모리 유형에 적재된 후, CPU가 처리 중인 데이터를 저장하는 레지스터에 적재.
캐시 메모리 : CPU가 가장 많이 사용하는 데이터. 처리 속도가 매우 빠르다.
레지스터 : 메모리 계층 구조의 최상단 요소. 연산 처리 속도가 굉장히 빠르다. CPU에 탑재되는 작은 메모리다. 저급 프로그래밍 언어를 사용하면 이런 메모리 유형에 직접 접근이 가능하다.
가상 메모리
컴퓨터 메모리 : 컴퓨터가 처리 중이거나 처리를 끝낸 데이터를 저장할 수 있는 공간
메모리 주소 (memory address) : 메모리 공간을 식별하기 위해 사용하는 물리적인 주소. (RAM이나 하드 디스크에 실제 데이터가 저장되는 공간)
가상 메모리 (virtural memory) : 운영체제가 물리적 주소에 가상의 주소를 매핑하여 실제 메모리보다 더 많은 메모리가 있는 것처럼 꾸며낸 메모리 영역.
페이징(paging) : 가상 메모리를 일정한 크기의 페이지로 나눠서 사용.
페이지 테이블 (page table) : 페이지에 매핑된 주소를 물리적인 주소로 변환.
선형 데이터 : 요소들이 서로 인접해 순차적으로 정렬되어 있는 데이터 구조. 이해하기도 사용하기도 쉽다.
선형 데이터 구조 : 배열
배열 (array)
- 특징
- 메모리에 데이터가 순차적, 연속적으로 정렬되는 선형 데이터 구조.
- 배열의 장점 : 요소들이 순차적 연속적으로 정렬되어 있어, 크기만 알면 임의의 순서로도 배열 내의 데이터를 읽을 수 있다.
- 배열의 한계점 : 배열 내의 데이터를 추가/삭제 시에는 배열의 인덱스를 다시 매겨야해서 처리하는 데에 오래 걸린다.
- 구성
- 요소 (element) : 배열에 저장된 각각의 데이터
- 인덱스 (index) : 배열의 요소에 매겨진 숫자
- 종류
- 1차원 배열 : 인덱스가 가리키는 요소가 하나의 데이터인 배열.
- 2차원 배열 : 프로그래밍으로 모든 요소에 접근할 수 있는 행과 열의 그리드. 여기에 데이터를 저장한 것을 행렬(matrix)라고 한다.
- 다차원 배열 : 인덱스가 가리키는 요소가 또다시 배열로 이루어진 배열.
선형 데이터 구조 : 리스트
리스트 (list)
- 특징
- 데이터가 흩어진 상태로 메모리에 저장되는 선형 데이터 구조.
- 연결 리스트(linked list) : 메모리를 효과적으로 사용할 수 있다.
- 노드(node) : 데이터 요소와 다음 요소를 가리키는 포인터의 쌍
- 헤드(head) : 해당 리스트에 진입할 수 있는 지점
- 구성
- 요소
- 포인터 (참조) : 리스트 내의 바로 다음 요소가 저장된 메모리의 위치를 가리킨다.
- 종류
- 단방향 연결 리스트 (singly linked list)
- 노드 하나가 다른 노드를 가리키는 포인터 하나를 갖는 유형의 연결 리스트.
- 마지막 노드는 다른 노드를 가리키지 않으므로 포인터는 널(null)값을 갖는다.
- 양방향 연결 리스트 (doubly linked list)
- 각 노드가 다음 노드를 가리키는 포인터와 이전 노드를 가리키는 포인터를 함께 갖는 유형의 연결 리스트.
- 양쪽 끝의 마지막 노드의 포인터는 안쪽도 가리키면서, 바깥 쪽의 null값도 가리킨다.
- 데이터를 삭제하거나, 리스트를 양방향으로 순회해야할 때 더 효율적인 연결 리스트다.
- 순환 연결 리스트 (circular linked list)
- 모든 노드가 원형으로 연결되는 유형의 연결 리스트.
- 마지막 노드는 첫 번째 노드와 연결되므로, null 값이 아니다.
- 노드 사이의 연결이 단방향일 수도, 양방향일 수도 있다.
- 버퍼링(다양한 처리를 원할하게 실행시키기 위해 버퍼라는 임시 저장 공간에 데이터를 저장하는 작업) 분야에서 자주 쓰인다.
- 단방향 연결 리스트 (singly linked list)
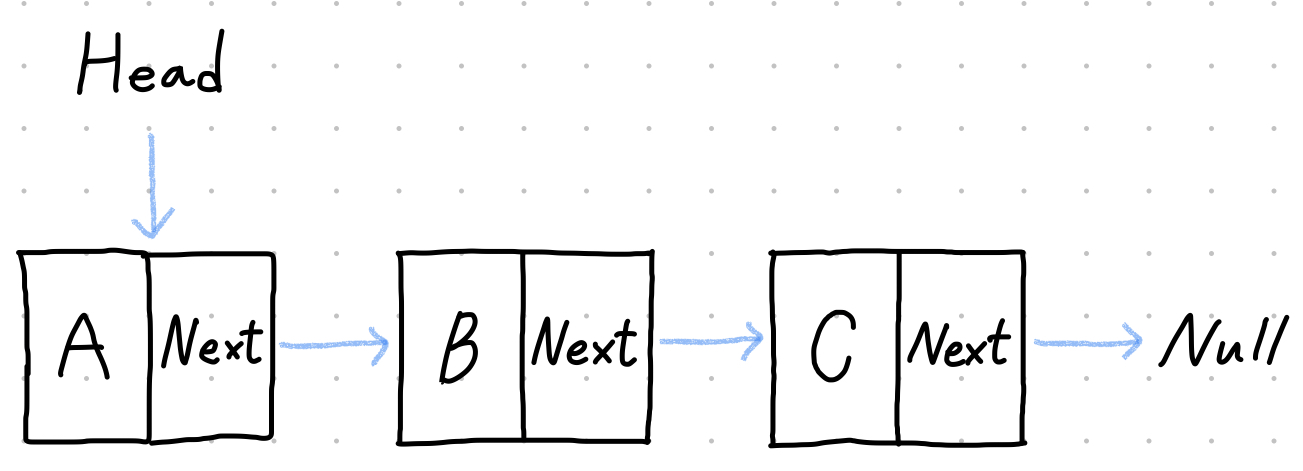
단방향 연결 리스트
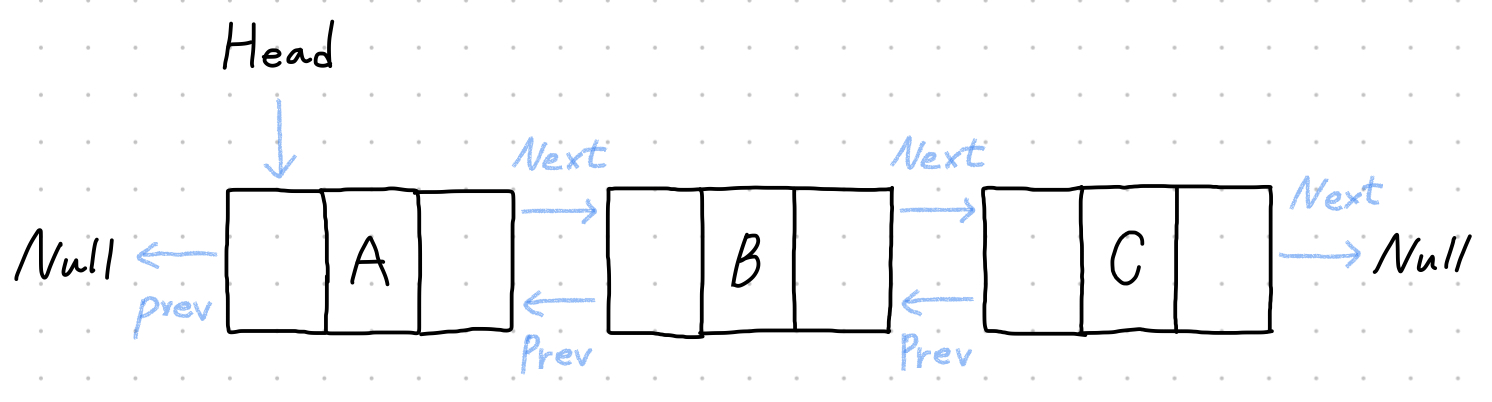
양방향 연결 리스트
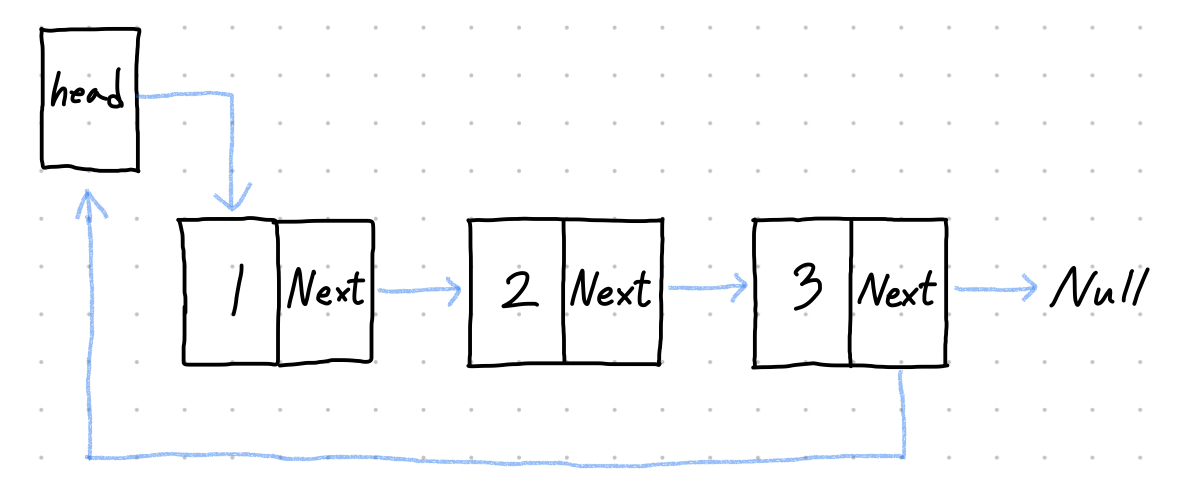
순환 연결 리스트
선형 데이터 구조 : 스택
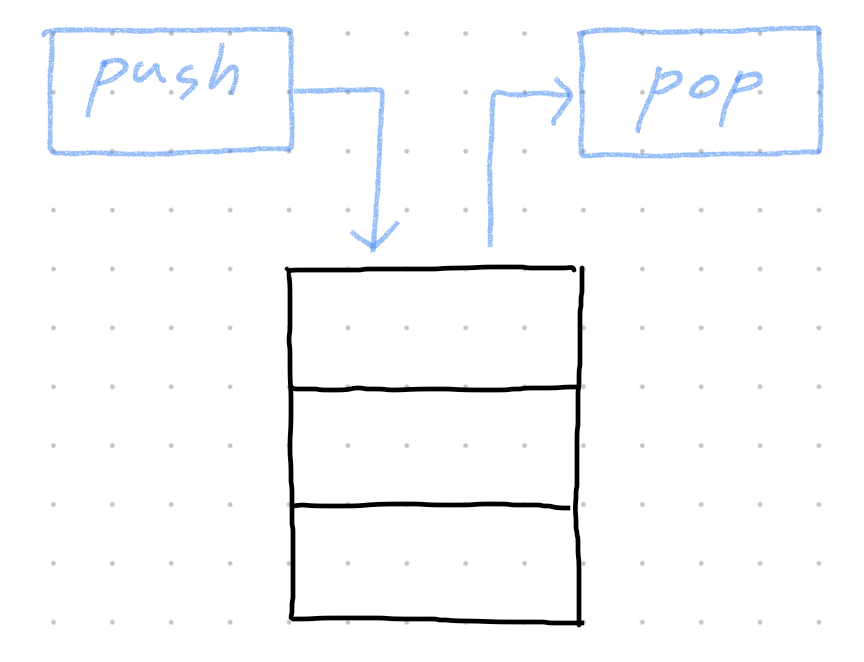
스택 (stack)
- 특징
- 추가된 요소를 사용 가능한 메모리의 가장 앞 주소에 배치하는 선형 데이터 구조.
- 후입선출(LIFO, Last In First Out) : 마지막에 추가된 요소를 먼저 삭제하는 스택의 구조
- 역추적, 문자열 반정을 위해서는 스택이 필요하다.
- 함수 호출, 스케줄링, 인터럽트 메커니증 등 다양한 기본 컴퓨팅 프로세스에 사용된다.
- 단점 : 최상단에서만 데이터 요소를 추가/삭제 할 수 있다보니, 스택 내에서 특정 요소를 검색할 경우 처리 속도가 느리다.
- 동작
- 푸시 (push) : 스택에 요소를 추가하는 동작
- 팝 (pop) : 스택에서 요소를 삭제하는 동작 (마지막으로 추가된 요소를 삭제한다)
- 종류
- 정적 스택 (static stack)
- 데이터 구조의 크기나 규모가 고정.
- 배열을 이용하여 설계할 수 있다.
- 동적 스택 (dynamic stack)
- 실행 중에 크기를 늘릴 수 있다.
- 크기뿐 아니라 소비하는 메모리의 양도 변한다.
- 최상단 요소를 가리키는 포인터가 있는 단방향 연결 리스트를 이용하여 설계할 수 있다.
- 정적 스택 (static stack)
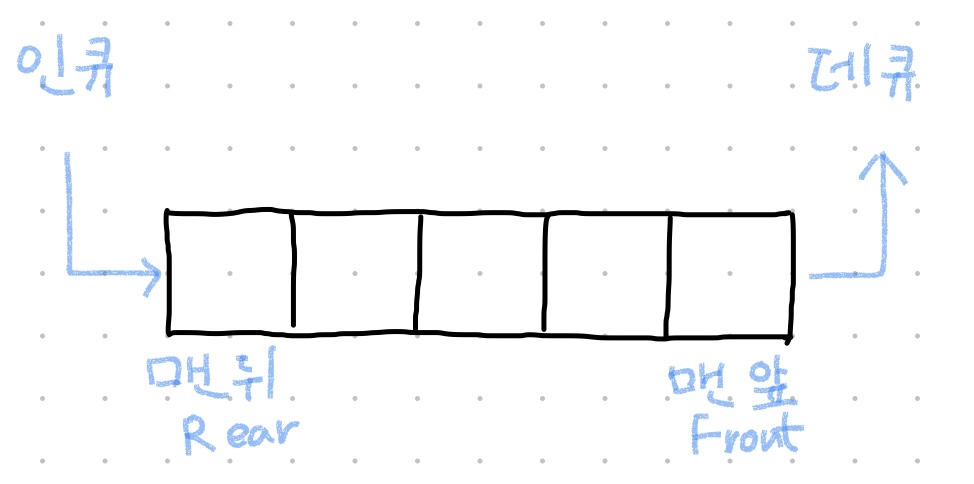
선형 데이터 구조 : 큐
큐 (queue)
- 특징
- 각 요소에 우선순위를 부여하는 선형 데이터 구조.
- 요소를 추가하면 큐의 뒤쪽부터 추가되고, 요소를 삭제하면 가장 오랫동안 있던 요소(큐의 앞쪽부터)가 먼저 삭제된다.
- 선입선출(FIFO, First In First Out) : 가장 먼저 추가된 요소가 우선적으로 삭제되는 데이터 구조.
- 동작
- 인큐 (enqueue) : 큐의 뒤쪽에 새로운 요소를 추가하는 동작
- 데큐 (dequeue) : 큐의 앞쪽에서 요소를 삭제하는 동작
- 종류
- 우선순위 큐
- 키(key)와 값(value)을 이용해 요소를 정렬.
- 키(key) : 값을 식별하고 검색. 모든 요소에 부여되는 우선순위를 표시.
- 값(value) : 실제 사용하는 데이터 값
- 연결 리스트나 배열과 같은 데이터 구조를 사용한다.
- 우선순위가 높은 요소는 낮은 요소보다 먼저 삭제된다. (우선순위가 갖다면, 먼저 추가된 순으로 삭제된다)
- 제공하는 메소드 : 요소 추가하기, 요소 삭제하기, 우선순위가 가장 높은 요소 가져오기, 큐가 가득 찼는지 확인하기
- 데이터 압축, 네트워킹, 컴퓨터 과학 분야의 응용 프로그램에 사용된다.
- 키(key)와 값(value)을 이용해 요소를 정렬.
- 선형이지 않은 큐
- 우선순위 큐