위로
아래
함수
- SELECT 문을 간결하게 만들어주고 DATA값을 조작하는데 사용.
- 주어진 인수를 처리하고 그 결과를 반환하는 기능 수행.
- 함수의 기능
- DATA에 대한 계산을 수행
- DATA를 다른 형태로 변환
- DATA 그룹의 결과를 출력
함수의 종류
- 단일 행 함수
- 함수가 정의된 sql문이 실행될 때 각각의 row에 대해 실행되며, row 당 하나의 결과를 돌려줌
- 인수로는 상수, 변수, 표현식들이 사용될 수 있음
- select, where, order by 절에 사용할 수 있음
- 복수 행 함수
- 그룹당 하나의 결과를 리턴해 줌
- select와 having절에 사용할 수 있음
- Group by 절에 의해 그룹화시킬 컬럼을 정의할 수 있음.
- count 함수를 제외한 모든 그룹 함수는 null 값은 처리하지 않음.
DUAL 테이블
- 더미테이블.
- 오라클에만 있다.
- 정해진 테이블 없이 연산을 사용하고자 할 때, FROM 절에서 사용할 수 있는 가짜 테이블.
SELECT 10*20 FROM dual;
DESC sys.dual;
SELECT * FROM dual;
CHR()
괄호 안의 숫자를 문자로 변환
--질문 75를 문자로 바꿔라
SELECT chr(75) FROM dual;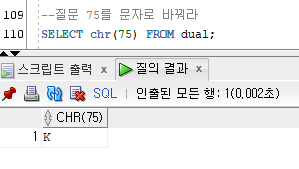
INITCAP ()
괄호 안의 문장에서, 각 단어의 첫 글자를 대문자로 변환
--각 단어의 첫 단어를 대문자로 변환
SELECT initcap('the soap') FROM dual;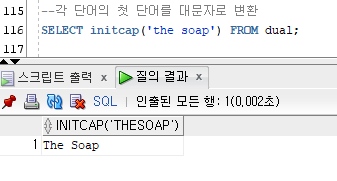
LOWER, UPPER ()
괄호 안의 문장을 모두 소문자, 혹은 모두 대문자로
--각 단어의 첫 단어를 대문자로 변환
SELECT initcap('the soap') FROM dual;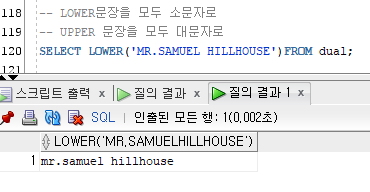
Lpad, Rpad ()
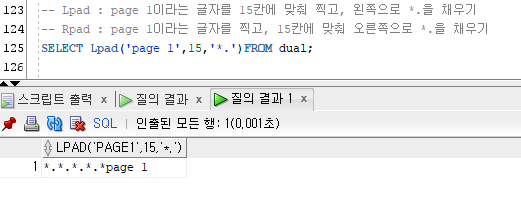
Lpad : page 1이라는 글자를 15칸에 맞춰 찍고, 왼쪽으로 *.을 채우기
Rpad : page 1이라는 글자를 찍고, 15칸에 맞춰 오른쪽으로 *.을 채우기
-- Lpad : page 1이라는 글자를 15칸에 맞춰 찍고, 왼쪽으로 *.을 채우기
-- Rpad : page 1이라는 글자를 찍고, 15칸에 맞춰 오른쪽으로 *.을 채우기
SELECT Lpad('page 1',15,'*.')FROM dual;
Ltrim, Rtrim ()
Ltrim : 왼쪽부터 시작해서 지정된 단어가 발견되면 제거
Rtrim : 오른쪽부터 시작해서 지정된 단어가 발견되면 제거
-- Ltrim : 왼쪽부터 시작해서 지정된 단어가 발견되면 제거
-- Rtrim : 오른쪽부터 시작해서 지정된 단어가 발견되면 제거
SELECT Ltrim ('xyxXxuLAST WORD', 'xy') FROM dual;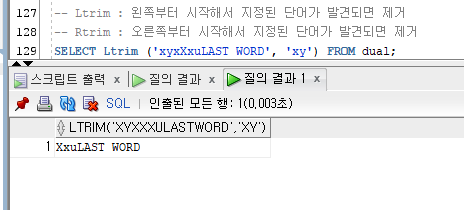
REPLACE ()
문장에서 지정된 문자를 찾아 다른 문자로 대체
-- JACK and JUE 문장에서 J를 찾아 BL로 대체
SELECT REPLACE('JACK and JUE', 'J', 'BL') FROM dual;

substr()
속성의 데이터를 개수만큼 자른다.
substr(속성,인덱스 번호,개수)
--질문 입사일이 2010년 이외에 입사한 사람의 모든 정보 출력
SELECT *
FROM emp
WHERE substr(hiredate,1,2)<>'10';
--질문 ABCDEFG 중 3번째에서 2개의 요소를 가져와라
SELECT substr('ABCDEFG',3,2)
FROM dual;
--질문 ABCDEFG 중 뒤에서 3번째부터 2개의 요소를 가져와라
SELECT substr('ABCDEFG',-3,2)
FROM dual;
USER
현재 어떤 사용자로 데이터베이스에 접속되었는지 알 수 있음
SELECT user
FROM dual;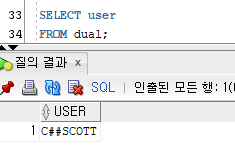
DECODE()
DECODE(검색 칼럽, 조건1, 결과값1, 조건2, 결과값2, ..., 기본값default)
if~then~elseif~end 와 같이 여러 조건을 부여하여 집계하는 경우에 사용
--질문 직무(job)이 analyst면 10%, 직무가 clerk이면 15%,직무가 manager면 20% 급여 인상
SELECT job, sal, decode(job,
'ANALYST', sal*1.10,
'CLERK', sal*1.15,
'MANAGER',sal*1.20,
sal) AS 오른연봉
FROM emp;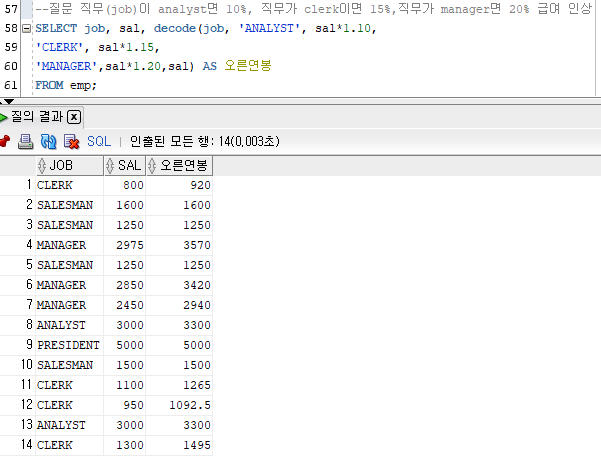
--질문 현재 근무하는 사원들의 월별 입사현황을 조사하려고 할 때
-- 1월부터 6월까지 월별로 입사현황을 decode함수를 이용하여 집계
SELECT COUNT(DECODE(TO_CHAR(hiredate,'mm'),'01',1))"1월",
COUNT(DECODE(TO_CHAR(hiredate,'mm'),'02',1))"2월",
COUNT(DECODE(TO_CHAR(hiredate,'mm'),'03',1))"3월",
COUNT(DECODE(TO_CHAR(hiredate,'mm'),'04',1))"4월",
COUNT(DECODE(TO_CHAR(hiredate,'mm'),'05',1))"5월",
COUNT(DECODE(TO_CHAR(hiredate,'mm'),'06',1))"6월",
COUNT(*) "전체"
FROM emp
WHERE TO_CHAR(hiredate,'mm')>='01'
AND TO_CHAR(hiredate,'mm')<='06';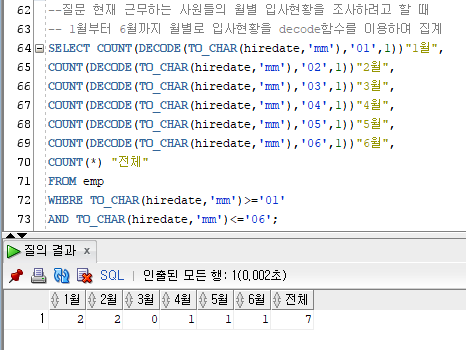
CASE()
SELECT CASE WHEN [조건1] then [결과값1] else [디폴트값] AND AS [설정할 이름] FROM 테이블명;
decode와 비슷하나, decode는 내부적으로 분류작업(sort)를 하여 성능 저하가 있을 수 있으나 case는 정렬 작업이 없다.
--질문 직무(job)이 analyst면 10%, 직무가 clerk이면 15%,직무가 manager면 20% 급여 인상
SELECT job, sal,
CASE
when job = 'ANALYST' then sal * 1.10
when job = 'CLERK' then sal * 1.15
when job = 'MANAGER' then sal * 1.20
else sal
end AS salary
FROM emp;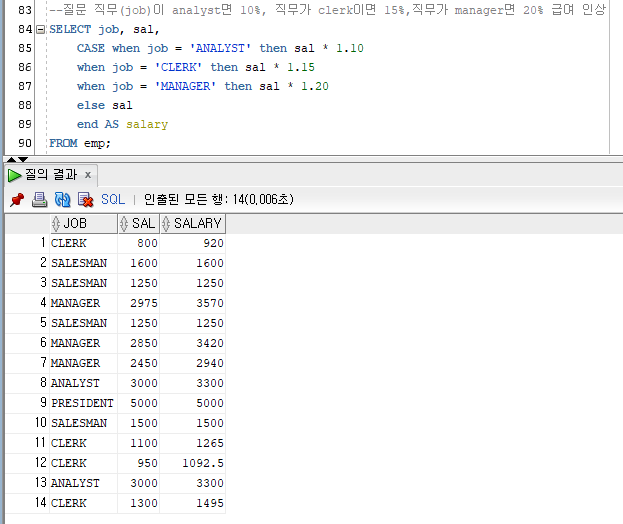
ROWNUM ()
기본형
SELECT ROWNUM,
a.*
FROM emp a
ORDER BY를 쓰려면 서브쿼리를 이용해야 한다
SELECT ROWNUM,
x.*
FROM ( SELECT a.*
FROM emp a
ORDER BY a.ename
) x
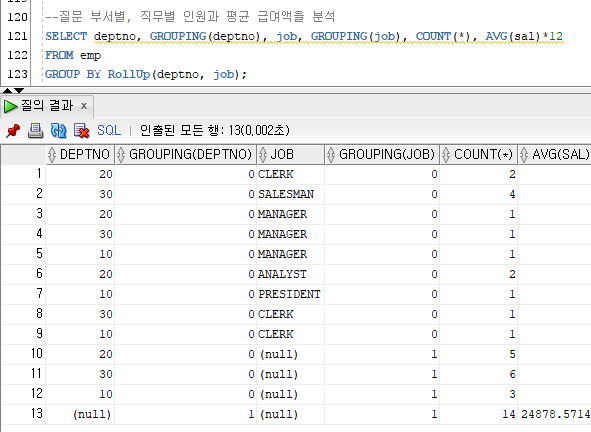
ROLLUP, CUBE ()
주로 crosstab(좌우, 위아래 형태의 합계를 내는 형태의 보고서)와 같은 보고서를 만들 때 사용하는 기능
RollUp
- 가로로 합계 내기
- SELECT ... FROM ... GROUP BY RollUp [컬럼1], [컬럼2],...;
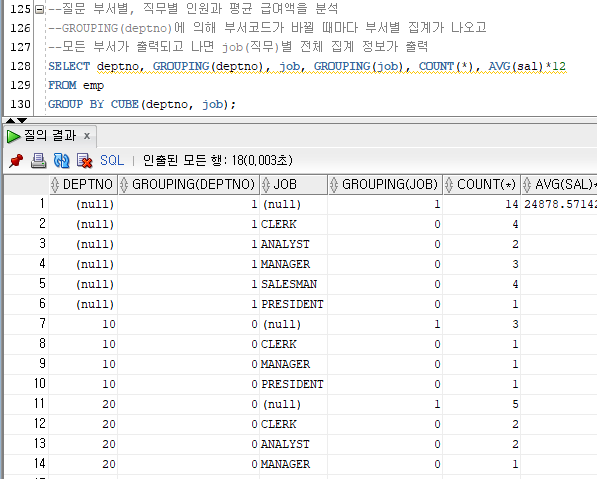
--질문 부서별, 직무별 인원과 평균 급여액을 분석
SELECT deptno, GROUPING(deptno), job, GROUPING(job), COUNT(*), AVG(sal)*12
FROM emp
GROUP BY RollUp(deptno, job);
CUBE
- 세로로 합계 내기
- SELECT ... FROM ... GROUP BY CUBE [컬럼1], [컬럼2],...;
--질문 부서별, 직무별 인원과 평균 급여액을 분석
--GROUPING(deptno)에 의해 부서코드가 바뀔 때마다 부서별 집계가 나오고
--모든 부서가 출력되고 나면 job(직무)별 전체 집계 정보가 출력
SELECT deptno, GROUPING(deptno), job, GROUPING(job), COUNT(*), AVG(sal)*12
FROM emp
GROUP BY CUBE(deptno, job);